
Revista N.° 74
Julio-Diciembre 2023
ISSN 1409-424X; EISSN 2215-4094
Doi: https://dx.doi.org/10.15359/rl.2-74.3
URL: www.revistas.una.ac.cr/index.php/letras
Definiteness and Specificity in EFL1
(Definitud y especificidad en el inglés como lengua extranjera)
Damaris Castro-García2
Universidad Nacional, Heredia, Costa Rica
Abstract
This article explores the application of English parameter settings to mark specificity and definiteness by Costa Rican Spanish-speaking, L2 English young adults. A Forced Elicitation Task (FET) was used to analyze the participants’ choices. The data were analyzed in comparison to native speaker responses. The results show that these EFL learners find it particularly difficult to decide on the correct articles for specific nouns, even more so if they are indefinite NPs. Indefinite and definite non-specific NPs are assigned articles with less difficulty. The results point to the consideration of spaced learning practice in the context under study.
Resumen
Se analiza el uso de los parámetros fijados para marcar especificidad y definitud en sustantivos en inglés, en un grupo de adultos jóvenes costarricenses. Para la recolección y análisis de datos se acude a un ejercicio de elicitación forzada cuyos resultados se comparan con la muestra obtenida de un grupo de hablantes nativos de inglés. Se detecta más dificultad para marcar sustantivos específicos, y más aun los sustantivos específicos indefinidos. Los sustantivos indefinidos y definidos no específicos muestran mejores resultados. El estudio invita a considerar el aprendizaje espaciado como una oportunidad de mejora en este contexto.
Keywords: definiteness, specificity, SLA, spaced learning, explicit instruction
Palabras clave: definitud, especificidad, ESL, aprendizaje espaciado, instrucción explícita
World languages implement varied systems to mark definiteness and specificity in their grammars. Whereas some systems use gender and number marking on articles (i.e., Spanish), other systems mark case explicitly on them (i.e., German), and still others lack article markers altogether (i.e., Japanese). For native English speakers, the English article system is often identified as one of those elements that gives non-native speakers away; mistakes with article use are easily spotted by native speakers. The English system, containing only two (or three) articles, appears to be relatively simple in terms of morphological and syntactic requirements, at least at first glance. This system does not mark gender or number but uses morphological markers that precede nouns in its grammar instead. In general terms, in English the marks definite nouns, a marks indefinite nouns, and no marking is needed for plural and mass NPs. However, a closer analysis of article distribution uncovers a different reality, as several other, sometimes overlapping, functions, need to be considered. As Snape3 maintains, “despite its simplicity, the English article system is semantically and pragmatically complex.” This may be why article choice remains a problematic issue even for advanced L2 English learners. This has been found to be the case of L1 Spanish speakers learning English, even though both Spanish and English articles are categorized on the basis of definiteness, and despite the fact that Spanish speakers achieve high levels of accuracy on tests measuring article use.
In this section, we will present the findings of research dealing with article use in L2 English learners and discuss some of the main theories explaining key aspects in the acquisition of definiteness and specificity in an L2. According to the Article Choice Parameter put forward by Ionin and others,4 languages specify their article systems lexically via a semantic parameter. They affirm that the universal semantic distinction is readily available to L2 learners. Based on the Article Choice Parameter, languages either encode the feature [+definite] (thus, activating the Definiteness Setting), or they establish the value [+specific] (activating the Specificity Setting). Ionin and others further propose the Fluctuation Hypothesis which states that L2 learners from article-less languages have full access to UG semantic parameter-settings. Learners thus fluctuate between specificity and definiteness settings until they are able to set the parameter to the appropriate setting, argue Ionin and others, who establish these concepts on the basis of studies involving learners of English whose L1s are article-less languages (Russian and Korean).
Prior to that study, Ionin and others5 had already analyzed the overuse of the in L2-English and they directly associated this overuse to the learners’ conceptualization of the specificity feature. They found overall native-like article-use patterns and precision in the use of the to mark definiteness and a/some to mark non-specific indefiniteness. However, they found learners alternate between articles to mark specific indefinites, particularly in wide-scope indefinite contexts. Ionin and others conclude that Russian and Korean L2 English learners decode English articles based on specificity rather than definiteness. They state that the root of these errors derives “from the learners optionally dividing English articles on the basis of specificity rather than on the basis of definiteness.”6 Their findings also show evidence of accessibility to UG and to the Fluctuation Hypothesis since learners can access the article parameters settings but fluctuate in their use of article choice until they are able to recode the correct feature. Ionin and others7 conclude that because learners from article-less languages exhibit a pattern similar to those from article-based languages, the features assigned to specificity come from access to UG, rather than from L1 transfer alone.
In another study, Ionin and others8 claim that one of the reasons why L1-Spanish learners are quite successful in the use of articles in English is because they make use of their L1 knowledge and thus classify English articles on the basis of definiteness, as they would in Spanish. This information, along with results obtained from L2-English learners whose L1 is not article-based, cause these authors to conclude that L2-English learners rely on three main sources to arrive at the correct semantic universal for English articles: L1 transfer, UG access (if parameter resetting is needed), and naturalistic or formal input. Ionin and others insist that when the option of transfer is available to learners, it will prevail over fluctuation. They add that the combination of all three factors—L1 transfer, UG access and input—is a key element to define the correct form-meaning adjustments that learners need to implement in their L2 grammars, as each of these factors aids another in leading learners to activate the correct settings.
Ionin and others9 further claim that, while article choice clearly deals with form-meaning associations, discourse is critical for learners to define whether a noun has a particular, unique quality (known by listener and speaker) that would render it definite. Discourse informs learners on which specification they need in the target language for article use. The fact that these specifications are not always readily identifiable for learners also makes it more difficult for them to draw direct generalizations. Ionin and others10 maintain that “acquisition of articles lags behind acquisition of other domains of the grammar, precisely because it involves discourse-based triggers.” Because L1 Spanish L2 English learners do not need to reinterpret these discourse-based triggers in English, they achieve (almost) target-like production of the adequate L2-English article system relatively easily, by relying on transfer from their L1. Once these learners harmonize the discourse context with the appropriate setting of the language parameter, accuracy grows stronger, and errors may be associated with issues related to lack of attention to contextual information.
García-Mayo11 agrees with Ionin and others12 that transfer overrides fluctuation in those contexts where learners can resort to both. García-Mayo concludes that L1 transfer is at work in article semantics because the Spanish learners of English in her study are highly accurate, in terms of the definiteness/specificity distinction. She notes that these participants reach close to native-like results due to their successful transfer of article semantics knowledge from their L1 into their L2. On the other hand, Deprez and others13 offer a perspective different from the fluctuation approach of Ionin and others14 and insist that instead of fluctuating, learners in their study exhibit a clear specificity bias. Their participants, learners from a definiteness-based language who are also learning a definiteness-based language, exhibit behavior similar to participants in the study by Ionin and others. Deprez and others state that if no evident difference can be identified between learners whose background includes no article or definite-based articles, it would not be justifiable to tend to a UG explanation rather than resorting to L1 transfer. Instead of referring to fluctuation, Deprez and others propose that the specificity bias pattern that can be identified points to a combination of a proficiency effect and an egocentricity-based account. These authors’ pragmatic account states that “while specificity involves an egocentric perspective based on a speaker-only frame of reference, definiteness involves common ground and perspective sharing.”15 Therefore they argue that the egocentricity account, as a computational limitation, may serve as a basis for adult L2 acquisition and would thus explain the specificity bias in similar results obtained from learners of different backgrounds: definite-based and article-less languages.
In another study, Snape and others16 analyzed how L2 learners from different L1s (Spanish, Turkish and Japanese) select articles to express generic reference. They investigated the role of L1 in L2 acquisition of definite NP-level generics and indefinite sentence-level generics, a feature that is shared, with certain distinctions, between English and Spanish. They determine that the Spanish learners outperform learners of other languages in selecting the for definite plural generics, Ø for bare plurals, with a limited incorrect selection of a/an in indefinite singular generics. They conclude that Spanish learners are able to shift the generic used for definite plurals (found in Spanish) to bare plurals (as used in English), thus adapting their superset grammar to a subset grammar. Although these authors find different evidence of L1 influence, they find it difficult to attribute their results to L1 transfer alone. According to their findings, L1 Spanish learners demonstrate the ability to choose the correct generic interpretation; however, Turkish and Japanese participants in their study yielded a similar tendency, a result that cannot be associated with transfer for the latter. Finally, Snape and others claim that the Spanish selection of Ø for bare plurals in English may come from the ‘Avoid Structure Principle’17. What this principle would entail in this context is that Spanish learners may avoid assigning a determiner to mark bare plurals and mass generics because they already know that the same interpretation is indeed available for bare NPs. Thus, by extension they apply this rule to bare plurals and mass NPs.
In a subsequent analysis, Snape18 studied the ability of L1-Japanese subjects to distinguish between the two types of definite categorizations: definite generic and definite unique interpretations. Under the premise that “[t]he definite generic can refer to a kind, whereas the definite unique denotes one unique individual,”19 he assumes that learners need to incorporate the additional feature [+species] to their grammars to be able to assign the generic interpretation. Snape argues that if the features [+definite] and [+species] are not part of the learners’ morphological repertoire in their L1, the difficulties dealing with the new syntax-semantic requirements encoded in the morphology of the L2 may be much greater. Snape further determines that L1-Japanese students are able to approach universal principles associated with unique/generic interpretations. However, he states that mapping of new morphology, like that of L2 articles, remains a defiant area in L2 learning. He concludes his study maintaining that definite generics are known to be particularly difficult for L2 learners.
In addition, Snape20 draws attention to the importance of “[e]xamining L1 transfer effects [because it] seems to be important in understanding why articles remain syntactically, semantically, pragmatically, morphologically, and phonologically complex (for some L2 learners).”21 Additionally, he draws a parallel between child and L2 article acquisition and asserts that L1 English children take time to develop a regular morphological use of articles and that the semantic-syntactic feature mapping, which is reflected in lexicon, is mastered later. A mismatch, along any point of this process, may then be very likely identified as the source of errors in L2 production. Snape asserts that, for learners whose L1 lacks articles, Ø would represent a default option. Given that articles may have a wide array of interpretations depending on the context where they appear, this interface plays a critical role. Figure 1 depicts the interplay of interfaces in article interpretation that Snape22 describes.
Figure 1. Internal and external interfaces in article use
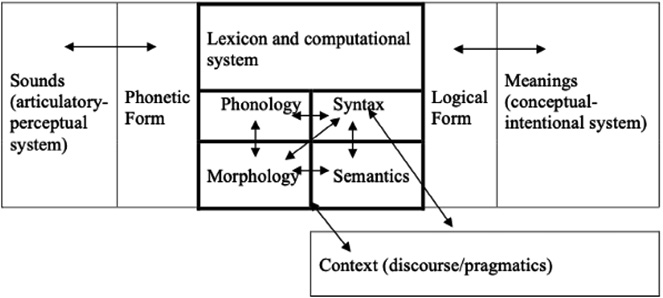
Source: Snape (2019), 10.
Snape23 further refers to the different roles that the elements in the system illustrated in Figure 1 play. The syntax-pragmatics interface has a fundamental role in assigning the correct interpretation to articles where context also has a critical role. Discourse, he insists, may also exert an influence on deciding the article choice for each context. The syntax interface may be influenced by the metalinguistic knowledge that L2 learners have acquired in terms of types of nouns and how they usually behave. We should not be surprised at the difficulty surrounding L2 article acquisition when we see how many different areas of language are involved in such task. This author concludes pointing out the evident transfer of L1 Spanish into L2 English. Furthermore, Snape also argues in favor of the importance of instruction in the form of positive and negative evidence to satisfy learners’ needs regarding article usage.
Along those same lines, Nasaji24 notes that, when it comes to L2 grammar acquisition, “explicit instruction can be overall more effective than implicit instruction.”25 Special attention should be given, then, to those cases where particular distinctions apply to the L2 in relation to the grammar parameters or the specific settings in place in our L1. Attention should be drawn to the differences between L1 and L2 that are known to be particularly difficult for L2 learners, as is the case of article usage. Achieving successful attainment of an L2 in formal settings requires forethought and careful planning of the curricula to ensure that topics, especially difficult topics, are addressed, ideally, more than once during the timespan of a university major, as is the case of the participants in the present study.
In summary, while there has been intensive research on second language acquisition of English articles, other studies offer different foci on the matter. For example, some studies have concentrated on the definiteness aspect of articles alone;26 or on working with learners coming from languages whose grammars lack an article system (as did Ionin and others27). Another examined the (non)generic reference of articles.28 Others studied the use of articles at the NP-level (the) and sentences-level generic (a) reference of English articles by L1 Spanish speakers, from the perspective of the influence of L1 over L229; or the level of fluctuation in article use as a product of semantic transfer of L1 features into the L2 system.30
The present research offers a general overview on the different uses that articles may have in combination with different kinds of nouns. In doing so, we attempt to direct attention to the importance of explicit instruction and an overt need for implementation of space learning practices in the SLA process. Considering the idea of the Article Choice Parameter,31 by which article-based languages vary in terms of how they represent articles (based on either definiteness or specificity) and recognizing that, for both Spanish and English, the ACP is already set for definiteness, we will try to determine what contexts and article forms represent the greatest challenge for the participants of this study. In so doing, we intend to describe what factors may be contributing to the difficulty of choosing the correct article form.
The present study offers a general perspective on the complete paradigm of L2 English article usage. Along the lines of Ionin and others32 and the description provided in Hawkins,33 a new test was designed. Nouns working under Construct 1[+def, +spec] require the use of the definite marker the. This notion refers to a specific item that both speaker and hearer know, either based on previous mention or shared general knowledge (i.e., the Eiffel Tower, the universe), partitive or locative use (the tip of your tongue, the roof of the house) or when the discourse and its context allow the participants in the conversation to identify the entity in question. NPs in Construct 2[-def, +spec] are elements which are not identifiable by the hearer based on the context or on what has been previously mentioned in the conversation, yet the speaker has a particular entity in mind. While a/an precedes singular elements in this construct, Ø precedes plural nouns which are presented to the hearer for the first time. Nouns following Construct 3[+def, -spec] are generic nouns which are marked with either of the articles, a/an, the or Ø (the precedes count, singular nouns). Nouns in Construct 3 refer to generic, (a) non-specific noun(s) that can actually be identified by the hearer due to general knowledge associated with the noun itself. Finally, nouns in Construct 4[-def, -spec] are preceded by a/an, or Ø. They refer to non-specific elements that cannot be identified by the hearer either on account of what has been said or from the context; they are also mentioned to the hearer for the first time.
This study contemplates an N of 46 native speakers of Spanish for T1 and an N of 34 participants for T2. These subjects were majoring in EFL Teaching at a public university in Costa Rica at the time of testing—that is, the entire population of students taking this major at this level. The exact number of participants in each data collection is affected by attrition and absences during the data collection session. These participants have an English level ranging between A2 (Elementary English) and B1 (Intermediate English) on the basis of the Common European Framework of Reference for Languages (CEFRL). The participants’ age shows a Mean of 20.1 and a Median of 19 years old. Data from a control group of 15 English native speakers is also analyzed. The data in this second group was collected 5 days upon arrival in Costa Rica as part of an exchange program where students take courses of Spanish as a second language. Their Mean age is 20.5 with a Median of 20.
A particular characteristic that should be considered for the Costa Rican group under study here is that these learners have been taught English (on and off) during their elementary, high school, and now tertiary education primarily by non-native speakers of English who have learned English from non-native speakers who in turn have also had the same language learning experience. This has been the case of a number of generations of English learners in the country during the past three or four decades. While this is not necessarily a situation that is particular to Costa Rica or Costa Rican students, it does represent a factor to consider given its possible implications in the learning process and endpoint language attainment. Students in this or similar contexts have a different set of linguistic skills at hand, and these elements have shaped their grammars. The situation is, indeed, clearly different from that of participants in previous studies which have taken place in settings where subjects were immersed in the target context or where the subjects might have had more input from English native speakers.
Participants were tested using a Forced Elicitation Task (FET), a new task created on the basis of Ionin and others.34 It consisted of 42 short dialogues in total. The third sentence of each dialogue was possibly missing an article and participants were asked to provide a/an, the, or Ø as required. The symbol Ø represents zero-article requirement in this context. This study reports on the results of two data collections for Spanish L1 participants; test 1 (T1) and test 2 (T2); and one data collection for the English L1 participants. The missing articles occurred before nouns located both in subject and object position. Additionally, for each of the notions [+def, +spec], [-def, +spec], [+def, -spec], and [-def, -spec], items included an array of noun forms: abstract, mass, count, non-count, singular and plural. Sample items are provided in (a) and (b).
(a) A. Did you hear about the new attractions on the farm?
B. Yes, I heard they have more horses and sheep.
A. That’s true. My little boy loved ______ horses; he didn’t want to leave.
(b) A. Do you like to study languages?
B. Yes, I love every aspect of it.
A. I think ______ grammar is a key aspect in learning languages.
This study was piloted with a control group of three adult native speakers of English. They took the written tests and provided target forms in all items included in them. After piloting the test with native speakers, it was additionally piloted with two groups of students from the same major. These students, however, were not part of the study but had followed the same curriculum as the participants. Once the study began, the data were collected during class periods in their official schedules (i.e., grammar, writing, oral production). The first set of data for this analysis was collected in February and the second in November 2020; that is, at the beginning and end of the academic year in this institution. Given the limitations created by the Covid-19 pandemic, the English L1 data collection took place in January 2023, when international students returned to our campus. The tests were given at the beginning of each class period so that students would not feel tired or pressured to finish the test in a short period of time. No time limit was imposed on the experimental task, but participants were instructed to read each dialogue thoroughly and choose the article they thought was most appropriate in each context. Generally, it took between 20 and 35 minutes to complete the FET. To avoid any type of data contamination and bias in the process, the researcher was never the participants’ instructor for the duration of this study.
After collection, data were assessed manually based on grammatical correctness. The results were entered into a SPSS35 database and analyzed to determine descriptive and inferential statistics. In the cases of Construct 3, which could allow more than one possible answer in some cases, they were both marked as correct and then entered into the database where they were again classified on the basis of the option provided by the student. In addition to comparing the results to the English L1 participants’ responses, the cases that permitted more than one correct answer were analyzed using Google N-gram Viewer36 (https://books.google.com/ngrams) to determine which of the possible options was more frequently used in the written literature of that database; these results were then compared to determine the likelihood of our participants producing (or avoiding) the most common forms. A Cronbach’s alpha analysis indicates a reliability of .75.
The first part of the analysis concerns the results obtained by EFL students in T1 and T2. As mentioned above, for T1 N is 46 while for T2 we have an N of 34. Graph 1 shows the overall results for EFL students in T1 and T2 for each one of the constructs: C1[+def, +spec], C2[-def, +spec], C3[+def, -spec], and C4[-def, -spec].
Graph 1. Results for T1 and T2 for EFL participants
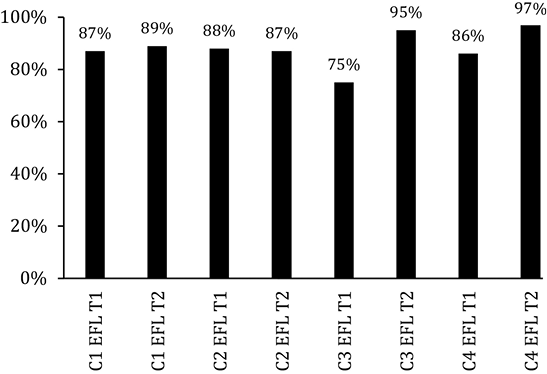
To analyze these results, a two-sample T statistical test was performed. An assumption of unequal variances (Welch T-Test) was considered. A p-value under 0.05 determines a significant difference between the two sample groups compared. In Table 1, we observe that there is a statistically significant difference between the results for C3[+def, -spec] and C4[-def, -spec]. All cases except C2, showing a statistical tie, reflect a better performance in T2 than in T1. All the following comparisons should be carefully considered as the N among groups is different and this affects the interpretation that can be given to its effects over the confidence interval. We should consider that, for those cases where the sample size is reduced, the standard error may increase as the confidence interval also widens.
Table 1. T-test to determine statistical differences in ESL participants between T1 and T2
|
t-test |
||||
|
t- |
df |
2-tailed Sig. |
||
|
Comparison by |
C1[+def, +spec] |
-0.6303 |
891.79 |
0.5287 |
|
C2 [-def, + spec] |
-0.5543 |
876.72 |
0.5795 |
|
|
C3 [+def, -spec] |
3.8315 |
693.95 |
0.0001389* |
|
|
C4 [-def, -spec] |
2.9938 |
691.11 |
0.002853* |
|
The following is a more detailed description of the results for each of the constructs in T1 and T2. Regarding C1[+def, +spec], where the noun can be identified based on the context, the use of definiteness in connection with singular, plural, mass, and abstract nouns was explored. Likewise, different types of contexts were analyzed, as is the case of shared general or contextual knowledge, overt previous mention of a noun, and partitive or locative nouns. Overall, students obtained a relatively high average of correct answers in this construct. With reference to the analysis of the different types of nouns and the type of knowledge of the participants regarding definiteness, across the different items, the percentage of improvement varied between 0.5 (item 22 ‘the evidence’) and 32.4% (item 35 ‘the toys’). For C1[+def,+spec], only three items obtained a lower rate of correctness in T2 than they did in T1.
4. A. Did you hear about the new attractions on the farm?
B. Yes, I heard they have more horses and sheep.
A. That’s true. My little boy loved ______ horses; he didn’t want to leave.
11. A. Chile’s economy has grown in the last few years.
B. They have a lot of good products in that country.
A. Yes, ______ wine that comes from Chile is becoming more and more popular.
28. A. I just talked to the lawyer. He said they reached an understanding.
B. Tell me more! What did he say?
A. All I can tell you is that ______ understanding they reached is not going to make you happy.
As can be observed, both items 4 and 28 have to do with previously mentioned nouns. However, while 4 included a plural count noun, 28 included an abstract noun. Item 11, on the other hand, included a mass noun. For 4 and 11, students may have applied the rule indicating that no article precedes plural and non-count nouns. As they selected the 67.7% of the time and zero 26.5% of the time for item 4; 88.2% chose the while 11.8% chose Ø for 11. As for 28, participants identified the abstract noun ‘understanding’ as count and wrote the 79.4 and an 20.6% of the time. In all cases, there is a clear majority of choice for the correct answer, but more students selected the wrong choice than they did in T1. Overall, this construct shows the second highest degree of accuracy in T1 (87%) and the third highest score of accuracy in T2 (89%).
Regarding C2[-def, +spec], where a specific entity (not identified by the hearer after mention) is in the mind of the speaker, we find singular nouns that may be marked as indefinite specific with a/an, or with Ø if plural. In this case, we identify improvement across different items in T2, the improvement varies between 6.5% (item 3 ‘a note’) and 12.4% (item 25 ‘a joy’). Interestingly, there is one group in C2[-def, +spec]—the singular abstract noun group—that still represents a challenge for participants in this study, even more so for some nouns than for others. All singular abstract nouns included in this task were immediately followed by relative clauses headed by the relative pronoun that, thus triggering the need for a/an before the abstract noun. In T2, accuracy was reduced from 91.3 to 85.3 for the noun ‘an understanding’ and from 80.4 to 64.7% for ‘a hopelessness.’ In the case of plural abstract nouns there is a reduction of accuracy that varies between 3.8 and 1.6%. These results suggest that most of these learners have recognized the fact that English exhibits zero marking when it comes to plural nouns; the indefinite marking in abstract nouns, however, clearly represents a challenge for learners at this point. The overall accuracy of correctness was reduced from 88 to 87% in C2; however, this difference is not statistically significant.
As for C3[+def, -spec], in reference to the definite generic category, where non-specific NPs can be identified as definite based on knowledge of the general characteristics of that noun, we find the following information. This construct shows the highest jump in statistically significant improvement. Accuracy rates improves from 75% in T1 to 95% in T2. Plural, mass, and abstract nouns rate of correctness in this category ranged between 94 and 100% in T2. Improvement, however, is particularly noticeable in items containing generic nouns, especially those that Snape37 claims to be identified through the feature [+species]. Items such as 5 and 32 for which the percentage of correct responses moved from 80.4 in T1 to 91.2 in T2, and from 69.6 in T1 to 85.3 in T2, respectively. These items are presented below.
5. A. Some animals have been studied to see how similar they are to us.
B. Is it true that some animals experience different emotions like we do?
A. Well, I read that studies show that ______ cat can feel emotions such as happiness or depression.
32. A. What type of pet do you want?
B. I want something different, a pet that is different from my friends’ pets.
A. You have to be careful. It cannot be any pet; ______ snake, for example, could be very dangerous.
Finally, C4[-def, -spec] is the second construct that shows significant improvement. C4 represents the third highest rate of correctness in T1 (86%), and it shows the highest rate of correctness in T2 (97%), which at the same time represents the most accurate use of articles in this study. Accuracy rates per item varied between 63% (items 42 and 10) and 100% (item 7) in T1, to 85.3% and 100 % (items 16, 7, 10, 20 and 29) in T2. The only item where a reduction of accuracy was observed was item 24 which is shown below. In this case, accuracy was reduced from 91.3% in T1 to 85.3% in T2.
24. A. People say that volcanoes are very active in Hawaii. Is it safe to go there?
B. Of course it is safe. Many people live there. Thousands of tourists visit the place all the time.
A. I know, I just hope ______ earthquake doesn’t strike while we are there.
These results come after an academic year in the subjects’ English major. While this could be expected after a year of instruction, it is important to point out that definiteness in English is only superficially studied in the grammar component of the curriculum (although it may be reinforced in the writing courses). Grammar instruction in the context under study is based on the information provided in the texts, Basic English Grammar,38 and Understating and Using English Grammar.39 There, the information on article use is included as part of Chapter 6 on count and non-count nouns in the former, and in Chapter 7 on nouns in the latter. The information provided is limited to a very general description of uses of articles in English. It explicitly mentions that a/an should be used before singular nouns; and the should be used with “specific (not general)” nouns and for the second mention of a noun. It also states that Ø is used to express generalizations.40 This information is complemented with two charts: Chart 7.7 Basic Article Use,41 and Chart 7.8 General Guidelines for Article Usage.42 The fact is that, in addition to the contexts explained in those texts, several other contexts are explored in this study. This may explain the lower results obtained here in comparison to those of other studies. Lack of direct instruction, reinforced through positive and negative evidence, along with the erroneous application of the limited number of rules studied in class, may cause students to have an incomplete knowledge of the different functions that articles may have.
Now, we will examine the results in T2 for the EFL subjects in comparison to the results of the Native Speaker (NS) group. The distribution of data is presented in Graph 2. As mentioned above, here it is important to recall the N difference and the effect it may carry over to statistical results. We have to keep in mind that larger samples convey more narrow confidence intervals and vice versa. Thus, we could expect an increase in standard error for the NS group, as each individual in that group has a greater impact in percentages.
Graph 2. Results for T2 in EFL participants and NS

Table 2 shows the statistical analysis of the performance of these two groups. The parametric statistical test used was a two-sample T-test with an assumption of unequal variances (Welch T-Test). As can be observed in Table 2, no statistically significant difference was found between the two samples, for any of the constructs, given that in all cases the p-value is above 0.05.
Table 2. T-test to determine statistical differences in ESL participants in T2 and NS
|
t- |
df |
2-tailed Sig. |
||
|
Comparison by |
C1 +def +spec |
-1.52030 |
425.54 |
0.1292 |
|
C2 -def + spec |
0.56880 |
352.81 |
0.5699 |
|
|
C3 +def - spec |
-0.35401 |
253.10 |
0.7236 |
|
|
C4 – def - spec |
0.34708 |
269.81 |
0.7288 |
|
As mentioned above, for C1 the overall performance of groups does not reflect a statistically significant difference. The degree of correctness is 89% and 92% for the EFL and the NS group respectively. There are a few cases where results will be further analyzed. In the case of items 11, 22, and 37, NS obtained a lower percentage of correct items than ESL participants. For item 11 (see item above), 80% of NS chose the and 20% wrote Ø; for ESL participants 88.2 chose the while 11.8% chose Ø. In this case, for the participants selecting Ø, the concept of wine being a mass noun prevails over the idea that tells us that the wine that comes from Chile is a specific wine. For the other two items, the choice of Ø is more puzzling given the fact that both involve a previously mentioned noun. In the case of item 22, 80% of the NS wrote ‘the’ and 20% wrote Ø compared to 85.3% of the EFL participants selecting the and 14.7 selecting Ø. Finally, in the case of item 37, 86.7% chose the and 13.3% chose a in the native speaker group, and 91.2% chose the, 5.9% chose a, and 2.9% chose Ø for the EFL group.
22. A. The attorney said they found new evidence in your sister’s case.
B. Really? What kind of evidence is it?
A. I don’t know much. They just said ______ evidence will help a lot in the trial.
37. A. Do you have everything you need for the barbecue today?
B. Well, I still have to prepare a salad and buy napkins.
A. Oh, I can prepare ______ salad you need. Don’t worry about it!
C2[+def, -spec] has a slightly lower percentage of correctness corresponding to 87% and 86% for EFL and NS respectively, resulting in a statistical tie. The comparison of article choice per item reflects a very close proximity of percentages between the groups, which in turn leads to the statistical tie. Most items range in accuracy between 94 and 100% for the EFL group and between 93.3 and 100% for the L1 English group. The items that reach lower percentages are items 25, 36, 6, 26 and 38. The first two analyze abstract nouns modified by a relative clause. For items 25 and 36, EFL participants reached 55.9 and 64.7% respectively while NS reached 60 and 73.3% in these items.
25. A. The kids really enjoyed the party.
B. Of course, children are the ones who enjoy Christmas the most.
A. It’s true. Maggie had ______ joy that I’ve never seen before in her eyes.
36. A. Visiting a war zone is an experience that changes your life forever.
B. What struck you the most?
A. I think there was ______ hopelessness that you could feel everywhere you walked.
Item 6 includes an abstract plural noun. It is the only item containing that kind of noun which reaches 86.7% accuracy (with Ø) for the L1 English group (13.3% selected the). For the EFL group, 85.3% used Ø and 14.7 chose the.
6. A. I love to talk about the trips that I have taken in the past.
B. You are lucky you have so many stories to tell.
A. Well, I have ______ memories of all my trips. Telling stories helps me remember things better.
Items 26 and 38 included plural nouns. While this is the first time these nouns are introduced in the dialogue and there is no reason to expect the hearer to identify them, 13.3% of native speakers selected the for 26 and 33.3% for 38. In the case of the EFL participants, 100% selected Ø for item 26 and 70.6% selected Ø for 38 (29.4% chose the).
26. A. In my house, the temperature is very cool. I enjoy being there.
B. Really? Mine gets really hot during the summer nights.
A. Well, in my case, I have ______ trees in the garden. That helps regulate the temperature inside.
38. A. I have a nice surprise for you.
B. Really? Did you get the tickets for the concert? How did you do it?
A. Well, you know! I have _______ contacts everywhere.
As for C3[+def, -spec], the same statistical tie observed in C2 is found here. An interesting tendency is identified in this construct, as for those cases where more than one answer was possible, both groups identify the same choice outperforming the other possibility. In some cases, the percentages are very close in both groups; in others, the NS group marks the difference between options more clearly. Items 5 and 19 show examples where participants find both a and the possible. In item 5, 91.2% of EFL learners and 93.3% of NS chose a, while 5.9% of EFL (2.9% selected the) and 6.7% of native speakers chose Ø, an answer that does not fit the given context. For item 19, 55.9% of EFL and 53.5% of the native group selected the, while 41.2% of EFL (2.9% selected a) and 46.7% of the native group opted for an.
5. A. Some animals have been studied to see how similar they are to us.
B. Is it true that some animals experience different emotions like we do?
A. Well, I read that studies show that ______ cat can feel emotions such as happiness or depression.
19. A. If you were an animal, what would you be?
B. I’d want to be a bird so that I could fly anywhere I wanted.
A. I think that ______ antelope is known for its speed. That’s what I would be.
In the case of items such as 21 and 23, 58.8% of the EFL participants and 73.3% of the NS chose the for the former (in both cases the rest opted for Ø), and 55.9% of EFL and 53.3% of the NS participants selected Ø for the latter (the remaining opted for the).
21. A. How was school today, Pete? What did you talk about?
B. Fine. They told us that there is a lot of water on earth. Is that true?
A. Yes. Our planet has more water than land on it. ______ oceans cover more than 70% of its surface.
23. A. Would you like to live in Alaska? A friend of mine is moving there.
B. Oh no! I wouldn’t. It is too cold there most of the time.
A. I would love it. ______ snow can be a lot of fun if you get used to it.
Other items within this construct reach very close overall percentages between groups. These range between 93 and 100 % and contain nouns such as cars, bees, health, and grammar.
Finally, in regard to C4[-def, -spec], when the results for T2 are compared, EFL participants have a better response ratio than NS. This is the construct where EFL participants perform best in the test. The overall percentage of correctness reaches 97% for EFL and 94% for NS. For items 2, 7 and 10, the NS reach 86.7% of correct answers in each case (Ø, an and an respectively), while EFL participants reach 94.1% in item 2 and 100% in items 7 and 10. In the case of NS, 6.7% selected an and the same percentage selected the in item 2, while 13.3% selected a for both 7 and 10.
2. A. Do you usually have fruit for breakfast?
B. Not often. I think it takes too long to prepare.
A. Well, you should get ______ oranges. They do not require a lot of work and they are pretty healthy.
7. A. This tea is too hot. I need to cool it down.
B. Wait a little! You don’t have to drink it all at once!
A. It is still hot, can you get me ______ ice cube from the fridge?
10. A. There are many different kinds of pets these days.
B. Some of them can be really unconventional.
A. Have you heard of anybody having ______ octopus at home?
The only item where EFL obtains a lower rate of correctness is 24, where 85.3% of EFL chose an and 14.7% opted for the; 93.3% of NS chose an and the obtained 6.7%. The rest of items in this group reached between 94.1 and 100% of correctness for EFL and between 93.3 and 100% for NS participants.
24. A. People say that volcanoes are very active in Hawaii. Is it safe to go there?
B. Of course it is safe. Many people live there. Thousands of tourists visit the place all the time.
A. I know, I just hope ______ earthquake doesn’t strike while we are there.
This study describes the participants’ ability to remap, when needed, the features of definiteness that they have incorporated into their grammars for Spanish onto the appropriate settings that the parameter requires in English. Both Spanish and English encode their article systems on the basis of the value definiteness. While there are several functions with a one-to-one correspondence for definiteness in Spanish and English, there are cases with clear distinctions. One of the most salient differences is probably the ungrammaticality due to the absence of a definite marker before plural nouns in Spanish, or its presence in certain contexts in English. The results of the latter, as well as several other functions, are discussed here.
After comparing the overall results of this study to those obtained in others, here we find that for C1[+def +spec], the results yield an overall similar percentage of correct responses as in Ionin and others,43 which in turn is outperformed by that of the participants in García Mayo.44 Percentages of 87 and 89 correspond to T1 and T2 in the present study while Ionin and others45 find a percentage of 87.5, and García Mayo46 reports 100% and 99.2% for intermediate and advanced participants respectively. As mentioned above, no statistically significant improvement is observed between the first and second data collection in the present study. These results provide us with interesting insights when considering the idea of L1 transfer suggested by García Mayo.47 We would have expected higher overall percentages in this construct given that its parameters exhibit a marked coincidence between English and Spanish. However, the percentage of correctness is the third and second lowest for these participants in T1 and T2, respectively. García-Mayo attributes the results of her study to L1 transfer into English and insists that in such a context transfer overrides fluctuation. That does not seem to be the case in our study.
For C2, results are also well below the marks reached in other studies, even for native speakers in this study (consideration should be given, as mentioned above, to the number of participants in each group and their effect on standard error). The overall percentage goes down in the second data collection for the present study, although no statistically significant difference is identified. The present study yields results of 88% (T1), 87% (T2) and 86% (NS). On the other hand, Ionin and others48 report 92.5%, and García-Mayo,49 93.75% for low-intermediate and 98.4% for advanced learners. In the case of the present study, we neither see an improvement on T2, nor find statistically significant changes between tests. The present results fall short when compared to the percentages shown in studies such as those mentioned above. The parameters of this construct are also very similar in Spanish and English; this makes the lower percentages in our participants even more unexpected.
A clear improvement is found in C3. Not only is an improvement identified between the data sets, but statistically significant differences are also found. The overall results for correctness move from 74% in T1 to 95% in T2, which allows the present results to approximate those of other studies a bit more closely. The notion [+def -spec] shows a higher accuracy rate of 96.7% in Ionin and others,50 and 100% and 97.5%, respectively, for low intermediates and advanced students in García-Mayo.51 A study carried out by Snape and others52 deals with generic interpretations at NP-level and sentence level. That study falls into the same category as those nouns in the notion [+def -spec]. Snape and others53 offer results more in line with those found in the present study, as they report 83% and 76% for intermediate and advanced learners in their study. The case of definite generics is being further analyzed in a separate study, as according to Snape, “mapping the features [+species] to the definite article to represent definite generic is problematic,”54 and that is one of the details that makes definiteness challenging even for advanced learners. While he may refer to participants of articles-less languages in that case, it has also been noted that “the use of the definite singular NP as a generic is rarely, if ever, mentioned in ESL books.”55
As mentioned above, the present study shows the most significant improvement in C3[+def, -spec]. T1 shows incorrect use of items such as those in 12 and 41, where 19.6% and 23.9% marked the noun as specific definite (using the) rather than selecting Ø marking. T2 reaches correctness of 94.1% and 100% respectively.
12. A. They complain that they didn’t get much from their parents.
B. Material possessions are not always the most important thing, you know.
A. True. I think ______ health is the best gift you can receive.
41. A. Do you like to study languages?
B. Yes, I love every aspect of it.
A. I think ______ grammar is a key aspect in learning languages.
Here it is also important to note that Ionin and others56 identified an unexpected pattern in Mexican Spanish speakers, as non-specific definites turned out to be more accurate than specific definites. For the latter, their subjects opted for zero marking in these contexts rather than using the expected the. This tendency is also identified in the present study, more for T1 than for T2. While non-specific definites reach 74% and 96% respectively, specific definites obtain 87% and 89% correctness rates in T1 and T2, yielding better overall results for the former over the latter. In our case, as mentioned above, this is interesting given that the most marked differences between Spanish and English are found in C3[+def—spec] while C1[+def, +spec] conserves more similarities with Spanish. Ionin and others57 justify their results by attributing the difference to a single item where, they argue, Spanish would require zero marking. Their item refers to the target NP house of Ben’s parents (which they compare to Fui a casa), for which most subjects used zero marking. They argue that Spanish does not require a definite marking there. We disagree with that analysis and assertion, as that is not necessarily the case given that Fui a la casa may also be used more—or as frequently—at least in Latin America, than the article-less form they propose. The explanation they relied upon may be reduced only to a regional variation.
For C4[-def, -spec], the present study shows an accuracy rate of 86% in T1 and 97% in T2. It is the most accurate construct in this study and the second best statistically significant improvement. Snape and others,58 who analyze singular, plural and mass nouns separately report the following results for intermediate and advanced learners respectively: for indefinite singular generics 83% and 86%, and for indefinite plural generics 92% and 91%. If we look at our results, the percentages for the indefinite singular range between 63% and 100% in T1 to 85.3% and 100% in T2. Indefinite plural generics move between 63% and 93.5% in T1 to 94.1% and 100% in T2. As noted, the overall percentages in T1 are lower in the present study, and we can also identify a wide range in the spread of results in all cases (except for plural generics in T2); that explains the statistically significant improvement in this construct. The rates reached in T2 in our study outperform those found in Snape and others.59
The overall percentages of correctness in the present study are a bit puzzling when considering the participants’ context and curricula, because the article usages contained in C1[+def,+spec] and C2[-def,+spec] (as well as C4[-def,-spec]) are those closer to parameters set for Spanish; and at the same time they are the uses that are part of the curriculum and that are included in the texts used by these participants in their grammar classes. We could presume that students may be concentrating so much on what they should not do, and on what is different, that they may be failing to notice what is possible. On top of the known difficulty that is assigned to article usage even for advanced learners,60 after considering the characteristics of our context, we may find different possible explanations for these results. First, we must consider the lack of explicit instruction and negative evidence for different uses of articles. Snape,61 elaborating on White,62 claims that the interaction of articles with key components of language is fundamental to understanding and using articles correctly. It is precisely the difficulty of integrating linguistic aspects that are brought forward to interact across the different core grammar interfaces what becomes problematic for learners. Snape63 additionally discusses the implications of the interaction between internal and external linguistic interfaces. For the purposes of this study, we will concentrate on two of them: the syntax-semantics and the syntax-pragmatics interfaces. The former has to do with the remapping of features that are part of the learners’ L1 onto lexical units. The latter would be that in charge of connecting the key core-grammar elements to one (or many in some cases) possible interpretations that any given grammatical sentence may have in a particular context.
The analysis of this study provides evidence for a ‘mismatch’ between those interfaces. For the former, we find cases where learners fail to remap a function that is part of the L1 onto the correct L2 function; thus, reassigning the incorrect article form to certain contexts or extending one to contexts where it is not correct. The latter is illustrated in cases where their metalinguistic knowledge tells the learners that there is more than one possibility; however, they fail to match the one that is often chosen by native speakers. Regarding this issue, Snape64 argues that “the discourse context may likely influence their choice of article, especially when the function of the definite article is a use which they are not familiar with.” That is, if they find an interpretation that clashes with what they know, they might discard it because it does not fit their explicit metalinguistic knowledge. Solving this type of problem would require explicit instruction and negative feedback in contexts such as ours.
In that sense, the role of discourse cannot be underestimated; on the contrary, students’ attention should be directed to it and its key role should be discussed in this classroom setting. Ionin and others65 insist that L1 Spanish L2 English learners are quick at reaching target-like production of articles because of the overlapping discourse-based triggers these languages share. Once learners have figured out the settings for article parameters shared between L1 and L2, the errors appearing can be more linked to discourse or context comprehension. Cases such as those of plural and mass nouns that do not require an article in English where there is no overlap between languages may take longer for students to master. Given that many English article functions are not overtly discussed as part of these participants’ curriculum, we may, once again, entertain the possibility of students requiring overt instruction in that area.
Snape66 also maintains that the syntax-pragmatics interface is key in assigning the correct interpretation that is immersed in context, which in turn is set up by discourse. Additionally, Snape points out that article choice responds to a chief influence played by syntax which is also fed by the metalinguistic knowledge learners have on how nouns behave. On that last point, he notes that positive and negative evidence is critical to quench students’ needs regarding article use. Once more, we must address the need for that component of the curriculum. Snape and others67 maintain that 3 factors are critical to ensure success in instruction: a. explicit instruction in the learners L1, b. intensive instruction spaced over an extended period of time, and c. clear instructions oriented to particular points of interest in article use, along with enough examples and practice. While at this level explicit instruction in the L1 may not be required, reference to L1 and L2 similarities and differences could be contemplated as a beneficial strategy. The authors claim that explicit instruction, and an adequate atmosphere for learners to create their own sentences using the target structure, can be advantageous for learners. At this point, output is necessary. It may come in the form of controlled output at first, turning into free production once the norms have been identified and internalized by learners.
Some of the results may be taken as an indication of a more conscious effort on the part of students to put into practice the metalinguistic knowledge they have gained in the major. Some evidence points to the participants’ efforts in remapping the Spanish superset grammar where definite plurals may have both specific and generic interpretation on the new function where definite markers lead to specific interpretations; thus, in generic contexts, students show a tendency to drop definite markers before plural and abstract nouns. There are also signs that show that the mismatch between students’ knowledge and common use found in N-gram Viewer (also produced by NSs) starts to change when two options are possible for mass nouns, as is the case of items 12 and 41 mentioned above. For example, T2 shows a closer alignment between the participants’ answers and the results found in N-gram viewer for these nouns: ‘Ø health’ is correct 78.3%, ‘Ø grammar’ is correct 71.1% in T1 and they reach 100% and 93.3%, respectively, in T2.
The intention of students in using their metalinguistic knowledge may translate into overcorrection, which may explain the drop in accuracy in some items. Given that this tendency is only observed in a few items, we could explain the increase in errors on the basis of isolated overcorrection, rather than an established rule in their grammars. For example, for item 4 (above), more students use Ø in T2 (26.5%) than in T1 (4.3%) for a previously mentioned noun: horses. This may be considered an indication of students’ awareness of the fact that while Spanish favors a definite generic marker before plural nouns; this would opposite render the use infelicitous in English. For item 11 (above), more students used Ø before the mass noun wine in T2 (11.8%) than in T1 where no one opted for that option. Finally, to name but a few, in T1 15.2% chose Ø before the abstract singular noun ‘understanding,’ which had been previously mentioned, while in T2 20.6% chose Ø. The participants in this study may have learned to drop the before abstract and mass nouns, just as they may follow the rule of dropping the definite marker before plurals. In these cases, participants may have a sense of what is not allowed in the target language but might not yet be familiar with those contexts where those constructions may be found.
The present study additionally supports claims made by Ionin and others68 regarding the combination of three main sources that learners rely on to assign the correct semantic universals for English articles; namely, L1 transfer, UG access (to adjust the parameters to the required setting in Spanish) and input. Snape and others69 identified different rates of accuracy from those elements transferred from L1 to L2. The situation is no different here; we find cases of successful and unsuccessful transfer. Transfer evidence may be connected to cases such as those pertaining to C1[+def, +spec], where there is complete coincidence between Spanish and English. Correctness in this construct may be interpretated as reliance on L1 as a point of departure in assigning L2 article functions. Additional evidence, in the form of erroneous L1 transfer, can also be identified in cases where Spanish requires the presence of a definiteness marker and English does not. Such cases are more frequently found in T1. In many of these cases, we find large percentages of answers where the participants apply the Spanish rather than the English rule. Item 41 (above) illustrates this case with 23.9% of the EFL participants adding the before grammar in that item.
Moreover, there are cases where participants may have resorted to UG. It was confirmed that definiteness in regard to the generic/specific distinction is not a topic studied as part of the curriculum in the participants’ major. The function is not likely studied in secondary school either. Quite the opposite, instruction is limited to specific concepts and article uses. Learners are instructed that mass nouns are not preceded by a or one; that for an indefinite article to be used there must be a unit of measurement before the noun; that mass nouns require the when there is a second mention of the noun; and that Ø marks generalizations and the marks specificity when preceding mass nouns. We explored knowledge of generic use of nouns in connection to C3[+def -spec], where there is an overall accuracy rate of 95%. An item such as 23 (see above) would require an understanding from students as to the semantic difference indicated by the use of the or Ø before the noun snow in that context. What makes this kind of items interesting is the very close percentage between the choices made by EFL learners in T2 and the NS group. As mentioned above, 55.9% of EFL participants and 53.3 % of NS chose ‘the.’ Universal Grammar may be at play here.
Furthermore, a combination of UG access and/or the effect of formal instruction can be attributed to cases such as item 12 (see above) and item15 where, rather than favoring the common form in Spanish through the use of the, students are implementing the set English parameters not shared with Spanish. They reach 94.1% of accuracy each. Cases such as these are far more frequent in T2, thus pointing to an evolution in grammatical accuracy. At the moment it is not possible to identify whether the grammatical knowledge reflected in article choice derives from input or UG access for remapping of functions. Finally, in the case of the participants in the present study, input may derive both from formal instruction and from incidental exposure due to access to media, leisure reading, and informal contact with English native speakers.
At this point it is essential to return to the importance of explicit instruction and spaced learning practices in this context. Some improvement is identified between the first and second data collections, having statistically significant differences in the cases of C3[+def, -spec] and C4[-def, -spec]. Still, several issues need to be addressed directly. Whereas the indefinite non-specific parameter obtains the most accurate results, the uses explored here bear close resemblance to Spanish uses. The second highest accuracy rate is assigned to C3[+def, +spec], which was not necessarily expected given the distinctions in settings for the parameter in this case. These results indicate that non-specific uses come a bit easier to ESL participants in this study.
In the case of article use before definite and indefinite specific nouns, the need for overt instruction and spaced practice is noticeable. The use of articles before a previously mentioned seems to be problematic for these participants. That is the case before count, abstract and mass nouns, where errors persist (up to 26.5% in one case). Errors in this type of use are particularly interesting given the fact that this use is explicitly taught to EFL learners as it is part of their curriculum. Finally, while non-specific definite and indefinite uses are relatively accurate, direct instruction and practice involving all kinds of nouns is needed, especially with mass and abstract nouns in these categories. Learners should be instructed on all possible uses of articles depending on different contexts. That would allow them to set the appropriate parameters in a way that resembles native-like use. This can be achieved through spiral practice on these different uses which would lead to efficient and effective learning that could be spaced across the major.
The analysis of the results shows that except for C2 [+def, +spec], where a statistical tie is found between T1 and T2, all constructs reflect better performance of T2 over T1. The most noticeable improvement is found in C3, for definite non-specific nouns, both in terms of response quality and correctness. When the data is compared against native speaker participants response, no statistically significant differences are identified. A statistical tie is present in the cases of C2 [-def, + spec] and C3 [+def, -spec] between EFL and NS participants. For C4 [-def, -spec], EFL T2 presents a better response ratio than NS; however, these results should be interpreted carefully considering the number of participants from each group (EFL N = 34, NS N= 15) and its effect on confidence intervals. Overall, the results of this study either approximate or appear below results of other studies discussed above, never outperforming participants in other studies. Unexpectedly, the constructs where closer similarities are maintained between English and Spanish are those obtaining lower percentages. This may be an indication of students concentrating on what is different, somehow dismissing the features shared between the TL and L1; further studies are required to prove this assumption.
These results are different from what has been found in other studies in terms of both yielding overall lower results and especially showing low results in constructs where Spanish and English share similarities. The distinctive features of the instructors involved with the L1 Spanish participants in our study should also be analyzed in depth in future studies with the intention of determining whether their learning background could have an effect on the results.
1 Recibido: 30 de octubre de 2022; aceptado: 19 de abril de 2023. Proyecto de investigación SIA 033-21, “Precisión en el uso de estructuras gramaticales en estudiantes del Bachillerato en la Enseñanza del Inglés: estudio de caso: Fase II,” Universidad Nacional, Costa Rica.
2 Facultad de Filosofía y Letras, Escuela de Literatura y Ciencias del Lenguaje. Área de Inglés. Correo electrónico: dcastro@una.ac.cr;  https://orcid.org/0000-0002-6352-1036. The author is grateful for the comments of several anonymous reviewers on earlier versions of this article.
https://orcid.org/0000-0002-6352-1036. The author is grateful for the comments of several anonymous reviewers on earlier versions of this article.
3 Neal Snape, “Definite Generic vs. Definite Unique in L2 Acquisition,” Journal of European Second Language Association 2, 1 (2018): 85.
4 Tania Ionin, Ko Heejeong and Kenneth Wexler, “Article Semantics in L2 Acquisition: The Role of Specificity,” Language Acquisition 12 (2004): 3-69.
5 Tania Ionin, Ko Heejeong and Kenneth Wexler, “Specificity as a Grammatical Notion: Evidence from L2 English Article Use,” Proceedings of WCCFL 22 Gina Garding and Mimu Tsujimura, Eds. (Somerville: Cascadilla Press, 2003) 245-258.
6 Ionin and others (2003), 257.
7 Ionin and others (2003).
8 Tania Ionin, María L. Zubizarreta and Salvador B. Maldonado, “Sources of Linguistic Knowledge in the Second Language Acquisition of English Articles,” Lingua 118, 4 (2008): 554-576.
9 Ionin and others (2008).
10 Ionin and others (2008) 254.
11 María del Pilar García-Mayo, “Article Choice in L2 English by Spanish Speakers: Evidence for Full Transfer,” Second Language Acquisition of Articles: Empirical Findings and Theoretical Implications, Maria del Pilar García-Mayo and Roger Hawkins, Eds. (Amsterdam: John Benjamins Publishing Company, 2009) 13-35.
12 Ionin and others (2008).
13 Viviane Deprez, Petra Sleema and Hakima Guella, “Specificity Effects in L2 Determiner Acquisition: UG or Pragmatic Egocentrism?,” Selected Proceedings of the 4th Conference on Generative Approaches to Language Acquisition, North America (GALANA 2010) (Somerville: Cascadilla Press, 2011) 27-36.
14 Ionin and others (2004).
15 Deprez and others, 34.
16 Neal Snape, Maria del P. García-Mayo and Ayse Gürel, “L1 Transfer in Article Selection for Generic Reference by Spanish, Turkish and Japanese L2 learners,” International Journal of English Studies 13 (2013): 1-28.
17 Gennaro Chierchia, “Reference to Kinds across Languages,” Natural Language Semantics 6 (1998): 339-405.
18 Neal Snape, “Definite Generic vs. Definite Unique in L2 Acquisition,” Journal of European Second Language Association 2, 1 (2018): 83-95.
19 Snape (2018), 85.
20 Neal Snape, “The Acquisition of Articles: The Story So Far,” Second Language 18 (2019): 7-24.
21 Snape (2019), 7.
22 Snape (2019).
23 Snape (2019).
24 Hossein Nasaji, “Grammar Acquisition,” The Routledge Handbook of Instructed Second Language Acquisition, Shawn Loewen and Masatoshi Sato, Eds. (New York: Routledge, 2017) 205-223.
25 Nasaji, 210.
26 Snape (2018).
27 Ionin and others (2004).
28 García-Mayo.
29 Snape and others (2013).
30 Snape (2019).
31 Ionin and others (2003).
32 Ionin and others (2004).
33 Hawkins, Roger. Second Language Syntax: A Generative Perspective (Oxford: Wiley-Blackwell, 2001).
34 Ionin and others (2004).
35 IBM Corp. IBM SPSS Statistics for Windows (Version 25.0) (New York: IBM Corp. 2017).
36 Google. Google N-gram Viewer (Mountain View, CA: Google 2010).
37 Snape (2018).
38 Betty S. Azar and Susan A. Hagen. Basic English Grammar (New York: Pearson Education, 2014).
39 Betty S. Azar and Susan A. Hagen. Understanding English Grammar (New York: Pearson Education, 2009).
40 Azar and Hagen (2014), 211-215.
41 Azar and Hagen (2014), 114.
42 Azar and Hagen (2014), 118.
43 Ionin and others (2008).
44 García Mayo.
45 Ionin and others (2008).
46 García Mayo.
47 García Mayo.
48 Ionin and others (2008).
49 García Mayo.
50 Ionin and others (2008).
51 García-Mayo.
52 Snape and others (2013).
53 Snape and others (2013).
54 Snape (2018), 93.
55 Snape and others (2016), 221.
56 Ionin and others (2008).
57 Ionin and others (2008).
58 Snape and others (2013).
59 Snape and others (2013).
60 Snape (2018, 2019).
61 Snape (2019).
62 Linda White, “Second Language Acquisition at the Interfaces,” Lingua 121 (2011): 577-590.
63 Snape (2019).
64 Snape (2019), 15
65 Ionin and others (2008).
66 Snape (2019).
67 Snape and others (2016).
68 Ionin and others (2008).
69 Snape and others (2013).


Escuela de Literatura y Ciencias del Lenguaje,
Universidad Nacional, Campus Omar Dengo
Apartado postal:ado postal: 86-3000. Heredia, Costa Rica
Teléfono: (506) 2562-4051
Correo electrónico: revistaletras@una.cr
Equipo editorial